AWS Lambda Container Image Support Tutorial
Use Machine Learning to detect objects in an image

Stackery Machine Learning Image Recognition Example
This is an example machine learning image recognition stack using AWS Lambda Container Images. Lambda container images can include more source assets than traditional ZIP packages (10 GB vs 250 MB image sizes), allowing for larger ML models to be used.
This example contains an AWS Lambda function that uses the Open Images Dataset TensorFlow model to detect objects in an image. When you invoke the /detector API route with a URL to an image the function will download the image, use the TensorFlow model to detect objects in it, then return an annotated version of the image back to the client.
Here is an overview of the files in this repo:
.
├── .gitignore <-- Gitignore for Stackery
├── .stackery-config.yaml <-- Default CLI parameters for root directory
├── LICENSE <-- MIT!
├── README.md <-- This README file
├── src
│ └── Recognizer
│ ├── Dockerfile <-- Dockerfile for building Recognizer Function
│ ├── font
│ │ ├── Apache License.txt <-- License for OpenSans font used for annotation labels
│ │ └── OpenSans-Regular.ttf <-- OpenSans font used for annotation labels
│ ├── handler.py <-- Recognizer Function Python source
│ └── requirements.txt <-- Recognizer Function Python dependencies
└── template.yaml <-- SAM infrastructure-as-code template
How to
The repository contains a complete example stack that can be imported directly into Stackery and deployed. The rest of this post walks you through building your own ML stack using Stackery.
Setup
- First, create an AWS account if you don't have one. Don't worry, everything we will do in this example will fit into the AWS Free Tier, and even if you do not qualify for the free tier you will incur fractions of a penny's worth of expense running this example stack.
- Second, create a free Stackery account. We will use Stackery to build the app and then deploy it into your AWS account.
- Follow the steps after creating your Stackery account to link your AWS account. This gives Stackery permissions to package functions and generate CloudFormation Change Sets but does not give Stackery permission to arbitrarily modify resources in your AWS account. You can find more details here: Stackery Permissions & Controls.
Create a new stack
- Once you have linked your AWS account it's time to start creating a new stack! Go to Stacks and click the green Add a Stack button. This will create a new, untitled stack for you.
- First things first, let's give our stack a name. Click the three dots next to the current stack's name (the current name will be something like Untitled or Untitled-1) and choose to Rename the stack. Now, pick a name (ml-image-recognition would work!) and save it.
- Before we go any further, why don't we save our progress? Click the big green Save with Git... button to authenticate to your favorite Git provider, create a new repo for the stack, and commit our starting stack.
Add a new HTTP API
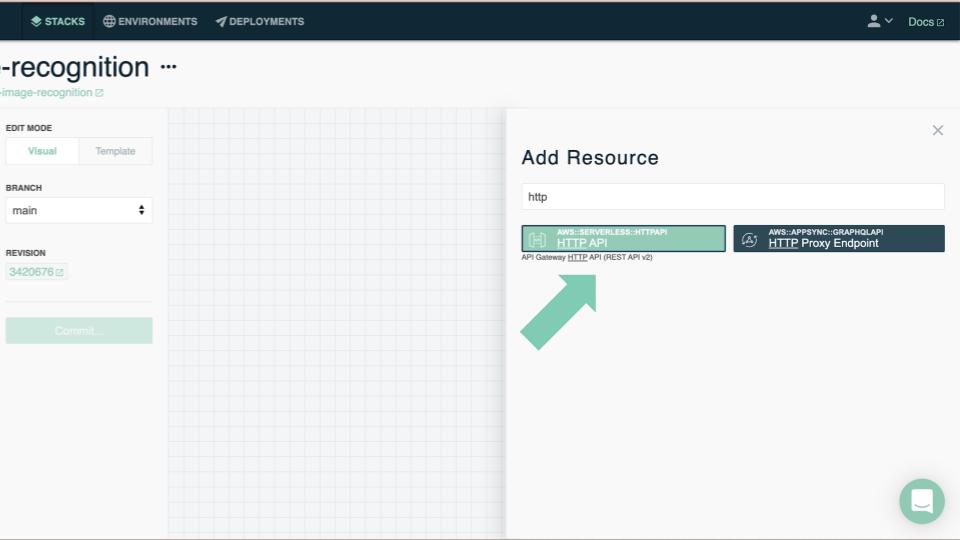
- We see a blank canvas for our new stack. Let's add an HTTP API! Click the green Add Resource button in the top right corner of the canvas. Click the HTTP API resource in the palette to add a new API to our stack. Close the palette.
- Double-click the new HTTP API (note: don't double click the GET / route, that opens the route settings instead of the API settings).
- Change the route from GET / to GET /detector.
- Click the big, green Save button at the bottom of the settings panel.
Add a new function
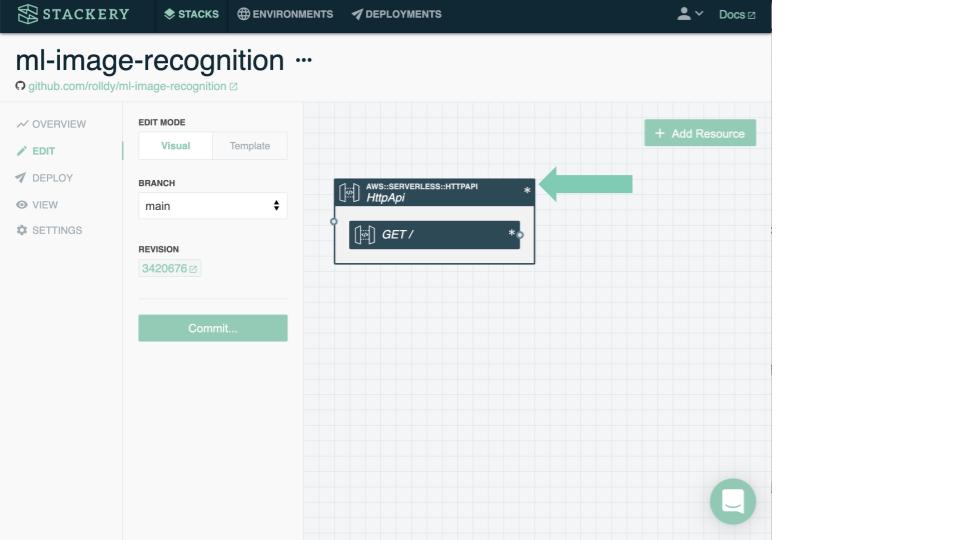
Now let's add a Lambda function! Again, click the green Add Resource button in the top right corner of the canvas. Click the Function resource in the palette to add a new Function to our stack. Close the palette.
Double-click the new Function to edit its settings.
Update the following settings:
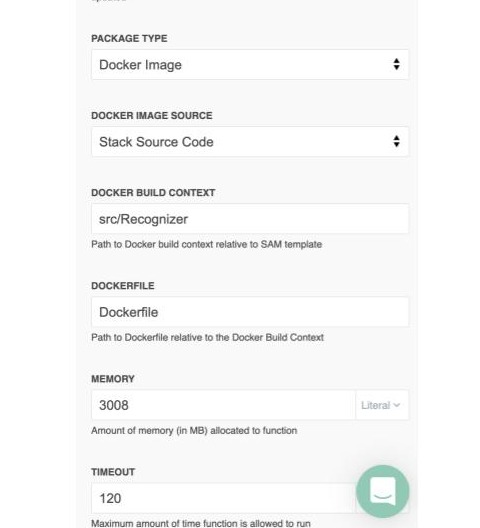
- Logical ID: Something descriptive, like Recognizer
- Package Type: Docker Image (so we can fit a large ML model into our source assets!)
- Docker Build Context: You probably want to update this from /src/Function to something like /src/Recognizer
- Timeout: 120 (it takes a while for TensorFlow to spin up!)
- Don't forget to click the big, green Save button at the bottom of the settings panel!
Save the stack by clicking the Commit... button. This is a great opportunity to see what we've added to the AWS SAM template by opening the Template Diff panel. Notice how a bunch of additional resources, like an AWS ECR container image repository and a CodeBuild project, are scaffolded to support building and running your new Function?
Edit your sources
- Now it's time to get our feet wet on the source code side! Pull down the stack's Git repo to edit it using your favorite editor / IDE.
- Scaffolded in the repo will be your function's source folder and Dockerfile. This Dockerfile will have a lot of possible starting points for you to choose from. We're going to build a Python Function, so you can take a look at the default Python Dockerfile commands. But since we're building a specific implementation, delete what's in the Dockerfile and replace it with the following:
# Download the Open Images TensorFlow model and extract it to the `model` # folder. FROM alpine AS builder RUN mkdir model RUN wget -c https://storage.googleapis.com/tfhub-modules/google/openimages_v4/ssd/mobilenet_v2/1.tar.gz -O - | tar xz -C model # Make sure it's world-readable so the Lambda service user can access it. RUN chmod -R a+r model # Build the runtime image from the official AWS Lambda Python base image. FROM public.ecr.aws/lambda/python # Copy the extracted Open Images model into the source code space. COPY --from=builder model model # Copy in the sources. COPY handler.py requirements.txt ./ # Copy the OpenSans font for annotation use COPY font ./font # Install the Python dependencies RUN python3 -m pip install -r requirements.txt # Tell the Lambda runtime where the function handler is located. CMD ["handler.lambda_handler"] - Now add the Python dependencies by putting the following into requirements.txt:
requests tensorflow Pillow - Lastly, add the Function handler source code into handler.py:
# Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved. # Copyright Stackery, Inc. All Rights Reserved. # SPDX-License-Identifier: MIT-0 import base64 from io import BytesIO from PIL import Image, ImageDraw, ImageFont import requests import tensorflow as tf # Detect and annotate top N objects NUM_OBJECTS = 3 # Loading model loaded_model = tf.saved_model.load('model') detector = loaded_model.signatures['default'] # Loading font font = ImageFont.truetype('font/OpenSans-Regular.ttf', 25) def lambda_handler(event, context): # Get image URL from `url` querystring parameter r = requests.get(event['queryStringParameters']['url']) # Detect objects from image objects = detect_objects(r.content) # Annotate objects onto image img = annotate_image(r.content, objects) # Encode image back into original format with BytesIO() as output: img.save(output, format=img.format) body = output.getvalue() # Send 200 response with annotated image back to client return { 'statusCode': 200, 'isBase64Encoded': True, 'headers': { 'Content-Type': img.get_format_mimetype() }, 'body': base64.b64encode(body) } def detect_objects(image_content): img = tf.io.decode_image(image_content) # Executing inference. converted_img = tf.image.convert_image_dtype(img, tf.float32)[tf.newaxis, ...] result = detector(converted_img) return [ { # TF results are in [ ymin, xmin, ymax, xmax ] format, switch to [ ( xmin, ymin ), ( xmax, ymax ) ] for PIL 'box': [ ( result['detection_boxes'][i][1], result['detection_boxes'][i][0] ), ( result['detection_boxes'][i][3], result['detection_boxes'][i][2] ) ], 'score': result['detection_scores'][i].numpy(), 'class': result['detection_class_entities'][i].numpy().decode('UTF-8') } for i in range(NUM_OBJECTS) ] def annotate_image(image_content, objects): img = Image.open(BytesIO(image_content)) draw = ImageDraw.Draw(img) for object in objects: # Multiply input coordinates, which range from 0 to 1, to number of pixels box = [ ( object['box'][0][0] * img.width, object['box'][0][1] * img.height ), ( object['box'][1][0] * img.width, object['box'][1][1] * img.height ) ] # Draw red rectangle around object draw.rectangle(box, outline='red', width=5) # Create label text and figure out how much space it uses label = f"{object['class']} ({round(object['score'] * 100)}%)" label_size = font.getsize(label) # Draw background rectangle for label draw.rectangle([ box[0], ( box[0][0] + label_size[0], box[0][1] + label_size[1]) ], fill='red') # Draw label text draw.text(box[0], label, fill='white', font=font) return img; - Save, add, commit, and push these changes up to your stack's repo.
Deploy the stack
- Now it's time to deploy the stack! If you have the Stackery CLI (you can install it from instructions here: https://docs.stackery.io/docs/using-stackery/cli#install-the-cli) it's as easy as running
stackery deploy --git-ref main(swapmainfor whatever branch your code is on). You can also point and click through our dashboard interface to deploy by navigating to the Deploy section on the left-hand sidebar after navigating to your stack at https://app.stackery.io..
Test
You can easily test the stack by opening the API in your browser. First, we need to find the domain name of your API. You can do this either from the Stackery CLI or the Stackery dashboard.
- Using the Stackery CLI: The Stackery CLI will print the domain name of your API after you deploy. You can also find it by running
stackery describe. - Using the Stackery dashboard: You can find the domain name of your API in the Stackery dashboard by navigating to the View section on the left-hand sidebar after navigating to your stack at https://app.stackery.io. Double-click on your API in the canvas view to find it's domain name.
Now, open your API in your browser by pasting in the url to your domain and appending /detector?url=https%3A%2F%2Fimages.pexels.com%2Fphotos%2F310983%2Fpexels-photo-310983.jpeg%3Fauto%3Dcompress%26cs%3Dtinysrgb%26dpr%3D2%26h%3D650%26w%3D940. This will tell the API to download this image and annotate it with the three objects it is most confident about identifying:
Note: It can take a minute or two for TensorFlow to load the image model and begin processing. This means the first time you use the API after a few minutes of inactivity it will timeout after 29 seconds while it is still loading. The Function will run to completion, but the HTTP API stops waiting after 29 seconds. So, try to hit the URL, and after a few timeouts you should be able to load the result. It takes less than a second to process the image when the Lambda Function is warm. If you want to ensure you always have a warm function, consider adding Provisioned Concurrency, though keep in mind the cost considerations of doing so.

Give a shout out!
We love hearing if we've helped folks learn more about AWS, serverless, or any other aspect of building this ML project! If you're so inclined, give us a shout out on Twitter @stackeryio. We'd love to send some thanks your way, too!
Related posts

